- ”My Job〜スキルシート〜“



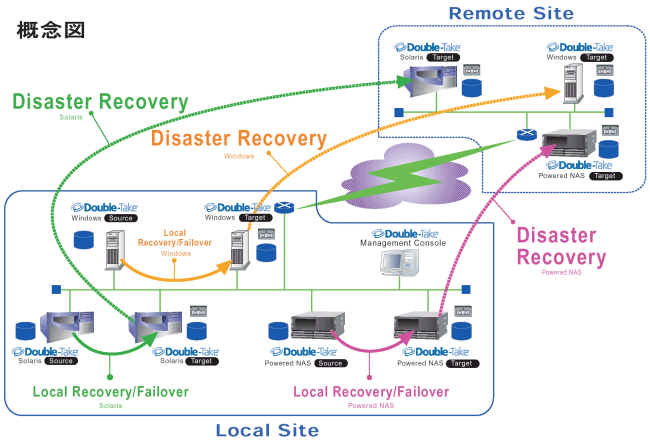
災害およびServer障害は、予兆も無く発生し、ビジネスにとって致命的な影響をおよぼします。 特に重要なビジネスデータが消失し再生不可能である場合は、企業の存続さえ危うくします。 CTCSPでは、このような災害/障害リスクを未然に防ぐ耐災害性(Disaster Tolerant) システムの実現に際し、 コンサルティングから設計、導入、監視、運営フェイズまでシームレス・スピーディーに対応致します。




■ Comments 前職はIS部門の一員として社内満足度を高める仕事に従事しており、IAserver周りを主に担当しておりました。 当然serverApplication周りの構築や運用のスキルはその時に得ました。 OSはWin95・Win4.0WS・Win2kP・Win4.0SV・Win2kSV・Sol2.6・Sol8・RHLinux7.0・etc・・・、 APPLIはMSSQL6.0・MSSQL2k・MSEXCHSV5.5・IIS4.0・IIS5.0・RAS・Printer・Virus対策・FTP・etc・・・、 NetworkではRouter・SWHUB・光ファイバー・FDDI・IP/VPN網(Radius認証)・FW(iij外注)の導入と運用を担当。 ASP言語での社内HPによるユーザ・マシン管理のWeb開発も行いました。 5年間勤めた後、お客様満足度を上げ、会社の売上に貢献する仕事に従事したく現在のCTCSPに転職。 そして現在まで至っております。 約1年間で得たスキルは上記のバックアップミドルウエアとWin・Sol・LinServer、そして、 Storageを組み合わせたシステム構築・営業同行・教育・トラブルシュート・セミナー講師です。 システム構築に絡むあらゆる環境設定・Appli構築方法・折衝力・外国の技術者との英語によるビジネスメール・ 企画資料・商品説明資料・インストレーションガイド・運用ガイドにおいて更にスキルアップ進行中です。すべて、 2ノードActive-Passive構築可能です。 Windows2k-MSSQL2k・Excange5.5・IIS5.0・Oracle9.2.0・WabSphere、Sol8・9-Sun One(iMS5.2・iDS5.1・ iWS6.0SP2・iDA1.2)・sendmal・qpopper・NFS・(Samba)・(FTP)・MySQL・InterScan・Tomcat Oracle(8.1.6)&9.2.0、RHLinux7.2〜9.0-Oracle9.2.0・Samba・(PostgreSQL)の構築が出来ます。 現在、RoseHA(クラスタソフトウエア)、DoubleTake(レプリケーションソフトウエア)等のプロダクトを通し、 製品紹介(技術者向け)、FAQ、実案件への はめ込み、懸念点洗い出し、線引き、ヒアリングシート作成、検証、 インストレーションガイド・運用ガイド作成、インプリメント作業、教育、保守、デバックと 一連のプレからバックエンドまで幅広く受け持っております。 また、会社の行き帰りや暇な時にはTOEICの教育プログラムをノートPCで勉強しています。(目標800点:現在500点… 外人とのコミュニケーションは何とかなります(^^;))今後はスキルアップの継続をしつつ、ITシステム コンサルタントの道を目指します。今後とも皆様の暖かいご支援ご鞭撻の程宜しくお願いいたします。
■ 用語説明
・ディザスターリカバリとは?
いわゆる障害時におけるデータの保護を目的としたシステム構築の事。
普通はStand-byノードを別サイト(東京-大阪、北海道-オーストラリア等)に置きます。
自然災害・テロ・マシンの故障等でデータ領域が復旧不能になった場合
直前までレプリケーションをしていた予備のディスクから復旧できるシステム構築を指します。
テープバックアップでは毎日バックアップを取っていたとしても最悪1日分のデータが損失します。
また、テロや災害によりビルごと障害が発生した場合、同じサイトにあるデータは全て損失となります。
また、SLAを結んでいるデータセンターなどでは、データ管理は必須です。
そして、東海地方では政府からのお達しで、
数10km以上離れた場所にデータ保護のシステムを導入する事になっています。
いわば保険のような物ですが、今後ますます需要は増えていきそうです。
・データリプリケーションとは?
基本的にはターゲットServer(バックアップ)にてソースServer(元)のデータの複製をするという事である。
その方式には大きく分けて同期式・非同期式とあり、同期式はデータのDISKへのI/O要求が発生した直後
(メモリやDISKへのbuffer領域への書込みは除く)、カーネルドライバレベルでその
トランザクションをフックし、そのままターゲット側に書き込み順序を守って複製先に
書き込んだ後に自分に書き込みます。
すなわち、データの整合性という観点から見ると、ほぼ同期が取られているという利点があります。
しかし、その仕組み上データのレプリケーション速度のパフォーマンスに著しく影響を及ぼし、
データロスト量は非同期式に比べ大きいのです。
非同期式はデータのDISKへのI/O要求が発生した直後(メモリやDISKへのbuffer領域への書込みは除く)、
カーネルドライバレベルでそのトランザクションをフックし、そのままターゲット側に
書き込み順序を守って送るという仕組みである。当然非同期式は同期式に比べ高速であるが、
ターゲット側のデータを触った場合(非同期式ではタブーとされている)整合性が
取れないというリスクを背負っている。(変更されていると認識せずに変更を行ってしまう→
最悪データベースなどでは立ち上がらなくなる。)
Networkの遅延(WAN環境でのボトルネック)やターゲット側のDISKへの書込み処理速度による遅延
(LAN環境でのボトルネック)を考慮すると、必ずデータロストは起こります。その物理量を
ミニマイズする事とサイト障害におけるデータ復旧を目的にレプリケーションを行うのである。
わが社で扱うDoubleTakeは、非同期式を採用したレプリケーション機能に加え、
障害時(トリガーはPUBLIC IPアドレスへのポーリングのみ。サービスやデーモンの障害検知は
サードベンダーのソフトウエアにて行う。)に自動でフェイルオーバーを行うHA
(ハイアベイラビリティ)機能が付いている1粒で2度おいしいバックアップミドルウエアなのである。
・クラスタとは?
いわゆる障害時におけるサービスの継続を目的としたシステム構築の事。
(=HA&RB(ロードバランシング))
・ハイアベイラビリティとは?
自然災害・マシンの故障・Application障害等でサービス
(ここではServerを使った物全般を指す)の継続が不可能になった時、
その障害を感知して全く同じ構成で用意したStand-by側に自動で切替処理を行い、
必ず数分の後にサービスが再開される仕組みの事を指します。
(クラスタには色々な意味があるがここでの説明はここまでとします。)
我々の扱うRoseHAというミドルウエアではServerのみの障害対策をしており、
StorageにおけるDISK障害に関してはRAID5やRAID1にてヘッジをしています。
すなわち、こうしたシステム構築により、(WEB決済システム・DBによる業務処理・メールサービス等)
サービス停止による利益損失、社会的信用損失、利用者のストレスのリスクヘッジをする事である。
・ロードバランシングとは?
アクセスの集中するWebServer等を数台用意しておき、ラウンドロビン機能等を使って、
1台に集中せずに分散化するシステムを指します。有名サイトであればアクセス量増加に伴い、
アクセス・ダウンロードスピードの低下が懸念され、利用者のストレスになってしまう。
現在ADSL・IP/VPN網・光ネットワーク等のWAN環境の整備に伴いサービス提供側の
システム構築が今後のNET業界での明暗を分ける鍵となる事でしょう。
・Storageとは?
簡単に言えば、データが入っている箱の事である。
現在多くのタイプのStorageが市場には存在しており、その用途により様々な使い方をされている。
次に上げる共有Storageもそうである。
中にはStorageのCPUを使用し2台でレプリケーションを行う物もあり、
(Storageレプリケーター等)稼動ServerのCPUを使わない“ZERO IMPACT”と
呼ばれる仕組みもある。
接続方式もSCSIや再起動のいらないFC(ファイバーチャネル)やiSCSI
(ネットワーク越しにデータを送受信する)
があり、ビジネスデータの増加に対するTCO削減はStorageの一極集中化による
BUテープ装置の削減や新たなシステムの導入費用の削減や
システム導入による人的作業コストの削減が可能となります。
また、安いNASが市場に現れてからは管理形態、運用方法等で管理者の選択が幅広くなってきている。
・共有Storageとは?
HAシステムにおいて2台以上(RoseHAは2台専用)のServerから、1つのStorageに繋げる事で
障害時に切り替わった時にデータの不整合性をほぼなくすために使用されます。
(厳密に言うと一時的に書き込まれるメモリ領域やDISKのbuffer領域のデータは救えない)
すなわち、メールServerで言えば、送る前のメール・送ってきたメール・
メールを送受信するApplicationのConfig(設定)情報・ユーザー情報・グループ情報等が、
この共有Storageに入っており、Application障害やServerCompornent障害時に切り替わった時に、
Stand-by側でその情報を引き継ぎ、あたかも今までのserverが生き返ったようにするための
必須アイテムです。
ここで分かる通り、この共有Storageが雨漏りで濡れてしまったり、Compornent障害
(電源・RAID コントローラー・SCSI・RAIDでヘッジし切れないHDD障害等)が発生した場合、
復旧するまでの時間がダウンタイムとなるわけである。その為にほぼ必ずStorageの保守は
24時間365日のオンサイト保守が用意されいつ障害が起きてもEngeneerが駆けつける体制をとります。
我々の扱うコアマイクロ社製Storage製品群はCompornent障害に着目し、
電源・RAID コントローラー・SCSIにおいて二重化をし、HDDに関してもRAID1、RAID5+HS等の
リダンダント機能が付いており、NO SINGLE POINT OF FAILURE(単一点障害の回避)
を実現しております。
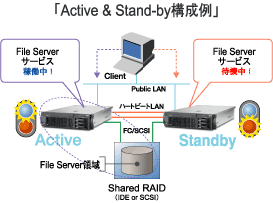
・Active&Stand-byとは?
全く同じ設定をした2台のマシンを、1台はサービスを供給するために稼動し、
もう1台はそのマシンに障害が発生した時のために稼動準備をしておく。その仕組みの事を指します。
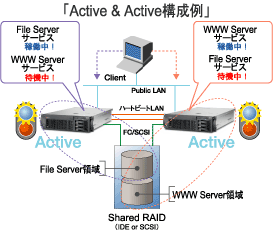
・Active&Activeとは?
上の“Active&Stand-by”を例えばメールserverで構築し、逆向きにWEBServerを
“Stand-by&Active”で構築すると、“Active&Stand-by”において普段は使用しない
CPU・メモリ等の資源を有効活用しつつ、もう一方のServerの障害の稼動準備もしておくことが出来る。
当然、障害時には2つのサービス(メールとWEB)が同時に動くだけのCPU・メモリ等の
サイジングが必要である。
・ノードとは?
いわゆるServerの別名である。
・TCOとは?
TOTAL COST of OWNERSHIP→管理に掛かる費用の事で、利益を生まないIS部門の費用を
運用方法の簡素化や自動化、マニュアル化により削減し余裕の出来た時間で開発等を行い
会社の利益を生むという思想があります。その中で生きてくるのが、我々のIP BACKUP 製品であります。
・OSとは?
オペレーションシステムの略で、Windows2000やSOLARIS8やRED HUT LINUX7.2などがそれにあたる。
あなたの使っているOSはと聞かれても困らないようにしておきましょう。
・Applicationとは?
いわゆるソフトウエアのことである。OFFICE2000やSENDMAILやIISも当然Applicationである。
・NO SINGLE POINT OF FAILUREとは?
必ず二重化されており、1つ壊れてもシステムの運用には影響が無い仕組みです。
当然2つ壊れた場合、ダウンタイム発生となります。
・DB(データベース)とは?
ある目的のために、関連性のある一定の情報を集めて使いやすいようにした物を言います。
エクセルなんかで表を作った事があると思いますが、それも一つのDBです。
WebServerの表の作成において、HTMLやASPでは単にファイルを作成するという意味合いが強く、
何らかの処理を行うには手順が複雑になってしまいます。Accessなどとのデータベースと連携できれば、
ブラウザ側は検索、抽出を行うための簡単なコマンド(クエリ)をデータベース側に送るだけで、
自動的に並び替えを行ってくれるため、あとは得られたデータをhtmlとして
表示させるだけという簡単なプロセスで済みます。
DBのApplicationとしては、Oracle8i・9i・MSSQL2000・PostgreSQL等がありそれぞれ、
OSや使用用途によって使い分けられている。
・トランザクションとは?
「データがおかしくならない為には最低限グループ化しておかないといけない処理単位」のことを
言います。例えば、2つのテーブルの同一属性に対する更新を行いたい場合、その2つのテーブルへの
更新は、「2つとも成功する」か、「2つとも失敗する」かのどちらかでないとなりません。
これら2つのテーブルの同一属性へ更新する処理を1トランザクションと言います。 仮に、
トランザクションの概念がなくて、一方のテーブルの更新だけ成功して、もう一方のテーブルの更新が
失敗して処理が終了してしまった場合、「データの整合性が崩れた」とか「データの不整合が発生した」
とかというように言います。
通常、トランザクションの開始は、"BIGIN TRANSACTION ...." のようなSQLを発行し開始し、
トランザクションの終了は、"COMMIT"あるいは、"ROLLBACK"を発行して終了します。
MS Exchange Server や OracleやSQL等ではトランザクション処理中に障害が発生すると、
立ち上がらなくなりロールバック(1つ前に戻る)を行う必要がある場合がございます。
(MSSQLは自動処理で行い、Exchangeはjetdbの復旧をトランザクションログから行う。Oracleは障害発生
時の倒し方も絡んできて複雑だが、ほぼ全て運用により回避が出来る用意がわがCTCSPにはございます。)
・SCSIとは?
SCSI(「スカジー」と発音します)とは、Small Computer System Interfaceの頭文字をとったもので、
コンピュータとさまざまな周辺機器を接続するための規格です。つまり、コンピュータと周辺機器を
つなぐ重要なパイプの役割を果たします。Small Computerという言葉からもわかるように、もともとは
小さなコンピュータ(おもにワークステーション)に向けられたインターフェースとして登場したもの
です。ところが、SCSIがもつ使い勝手の良さや汎用性の高さなどが受け入れられ、現在では、
パソコンから大型コンピュータにいたるまで、たいへん幅広い分野で利用されるようになりました。
SCSIは、いまや世界標準のインターフェースといっても過言ではありません。
・FC(ファイバーチャネル)とは?
FibreChannelは一秒間に1Gbpsの伝送速度を持った超高速データ伝送ネットワークです。
FibreChannelの上位層では、TCP/IP、ATM、SCSI等のプロトコルをサポートできます。
これによって今までのネットワークを統合し、ストレージディバイスをネットワークに直結する事を
実現できる点で、重要な意味を持っています。このためのOSやアプリケーションの開発は遅れては
いますが、近い将来ユーザがServerを経由せずに直接DISKから情報を取れるシステムが
できる予定です。実現されれば、無駄なトラフィックが発生せず、高速化された理的なネットワーク
運用が可能になります。
また、コンピュータ間のデータ伝送方式として、チャネル方式とネットワーク方式があげられます。
チャネル方式は広帯域、確実性を特徴としていますが、遠距離には適さず、接続には一般的に太い
ケーブルが使用され固定的である面等で自由度があまりありません。ネットワーク方式は接続の自由度
が高く距離の制限も少ないのが特徴ですが、物理的、階層的な理由により、伝送速度が遅いと
されています。
ファイバーチャネルはこのチャネルとネットワークの長所を併せ持ったものであり、
今あるネットワークの世界に大きな変化をもたらせる、革命的な開発目標と特徴を挙げています。
1.コンピュータや機器間を1本の全二重ケーブルで接続
これにより、接続が非常に容易になり、さらにパラレル(並列)ケーブルに比べて安く、
かつ距離を延ばす事(最長10km)ができます。
2.高速かつ拡張性に富むデータ伝送速度を提供
データ伝送速度が1Gbps(ギガビット/秒で正確には1063Mbps)をベースに、
この半分の532Mbps、さらに半分の266Mbps、また2倍の2Gbps、
さらに4Gbpsと非常に高速なデータ伝送速度を確保。
3.データ伝送距離は最長10kmとする
シングルモード光ファイバを使用した場合、最長10kmを目標とし、1つのキャンパス内であれば
1本のケーブルで接続可能。
4.少ない伝送エラーで最大のデータ伝送量を目指す
ネットワーク方式の無責任なデータ伝送方式に対し、ファイバチャネルではできるだけ上位レイヤに
再送をさせないように、伝送エラーを減らし、かつ精緻なフロー制御を行いながら、
万一のデータロスを瞬時に発見し修復。
5.各種の上位プロトコルを透過する
ファイバチャネルは高性能なデータ伝送手段かつ特定のプロトコルやデータ伝送手段には依存しないため、
ファイバチャネル上を、HIPPI、SCSI,SBCCといったチャネルデータからIP、IPX、
ATMといったネットワークデータに至るまで通過させる事が可能。また、将来、新しい種類のデータを
効率よく伝送する事もできます。
6.すべての機器を包含するネットワーク
従来は、スーパーコンピュータやメインフレーム用のチャネルには、HIPPI,
マルティプレクサチャネルまたはメーカー独自のチャネルを、ワークステーションやパソコンは
SCSIその他を、ネットワークにはEthernetやFDDIを、といっように機器によって
使い分けていました。ファイバチャネルは安価で高速しかも性格なデータ伝送手段を、
パソコンからスーパーコンピュータに至るまで幅広く提供します。
7.物理的、論理的に優れた接続性を持つ
新たな機器の接続やその変更に際し、特別な操作を必要としない、プラグアンドプレイを実現。
FibreChannelは動作中であっても、簡単に物理的接続作業を行う事ができ、論理的にも自動的に
ログインが行われ、使用者にとって煩わしい作業を要求しない事を目標としています。
8.市場にある部品技術を用いて機器を構成する
FibreChannelの実現のために、新たね部品技術の開発は必要と染ません。市場にある部品を使う事に
よって、安価に製品開発でき、設置や配線を行う事ができる様になる、コスト・パフォーマンスのよい
製品の生産が期待できます。
・iSCSIとは?
ストレージの世界で標準となっているSCSIのコマンドやデータをTCP/IPパケットの伝送フレームの中に
包み込み、SCSIコマンド体系を外から見えなくすることにより、ストレージ製品のIPネットワークへの
直接接続を可能にする。ストレージ製品がネットワークに直結できることにより、ネットワーク網を
構築するハブ、ルータ、スイッチ類は従来のものが利用できるようになる。簡単にそのメリットを
列記する。
1.既存のアプリケーションは、iSCSIを意識することなく従来通りローカル・ストレージに
アクセスするのと同じ手順でターゲット・ストレージのデータを読み書きできる
2.ディスクへの読み書きは、SANと同じブロックI/Oであり、NASのようなファイル・システムは
ストレージ側に必要としない
3.現在はSANのインフラ・スピード(1Gbps)とあまり変わりはないが、今後のイーサネットの
伝送スピードが10倍速(10Gbps、100Gbps……)で向上すると考えると、そのメリットは計りしれない
4.ネットワーク管理の面からも、ストレージ機器をほかの通信機器と同じように同一インフラ網上で
統合管理が可能
従来、サーバ機器の従属的な役割であったストレージ・デバイスが、SANやNASといった形でネットワークに
つながり、その機能もサーバに依存しない形態をとりつつ関連技術を発展させている。
しかしながらSANのネットワークは、通常のIPネットワークとは異なり、大容量かつバースト性の強い
ストレージ・データ転送に向いたファイバ・チャネルのインフラの上に構築されているため、
インターネットに代表されるIPネットワーク網と共存することはできなかった。
イーサネットのスピードが10/100Mbps当時は、この違いを埋めることができなかったが、
IPネットワーク・テクノロジーの進化に伴い、転送スピードの差はなくなり、かつネットワークに
対する二重投資に素朴な疑問も出てきた。そんな環境下でのiSCSIの出現は、
極めて自然といえるかもしれない。
iSCSIの標準化は、Internet Engineering Task Force(IETF)のIP Storage Working Groupで
行われており、Internet-Draftとして公開されている。現在、技術的な仕様は固まっており、
編集上のコメント処理を残すのみとなっている。
Storage Network Industry Association(SNIA)のIP Storage Forumは、
iSCSIの標準化のサポートを行っており、iSCSIの普及活動を推進している。
・RAIDとは?
複数のディスクを並列に接続し、その全体をまとめて制御することにより、高速性・障害耐久性の向上を
図ったストレージ技術をRAIDと呼びます。RAIDの採用を薦める理由としては、
『 ディスク障害におけるデータ損失の軽減 ・ ディスク障害における無停止システム稼動 ・
ディスクアクセス効率の向上による高速化 ・ ディスク障害における復旧時間の削減 』などが
あげられます。このRAIDを制御するレベルには、次のような種類があります。
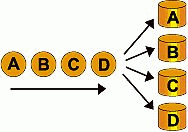
1.RAID 0 (ストライピング)
複数のディスクにデータを分割して同時に書き込むため、最も高いディスクアクセスのパフォーマンスを
得られます。ただし、ディスク障害によるデータ保護機能はありません。
2.RAID 1 (ミラーリング)
2台のディスクに同一データを同時に書き込み、冗長性を図る構成。ただし、高速性・経済性は劣ります。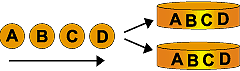
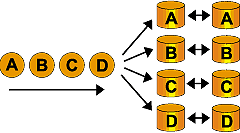
3.RAID 0 + 1 (RAID 10)
RAID 1 で構築した複数のグループに対して RAID 0 の設定を図り、高速性と大ボリュームを実現した
構成。ただし、多ディスクのため経済性は劣ります。
4.RAID 0 + 1 + スペアディスク
RAID 0+1 構成にディスク障害時のスタンバイドライブを設定。ディスク障害と同時に高速な復旧をめざす
RAIDレベル。
5.RAID 3
複数台のディスクのうち1台をエラー訂正のためのパリティ記録専用のディスクにし、
ディスク障害時にパリティディスクによる冗長性とデータ分割記録による高速性を図った構成。
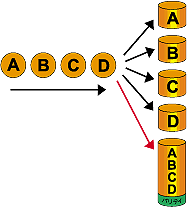
6.RAID 3 + スペアディスク
RAID 3 構成にディスク障害時のスタンバイディスクを設置。ディスク障害と同時にスペアドライブに
復旧データを自動的に書き込み、その間もRAID稼動が可能なRAIDレベル。
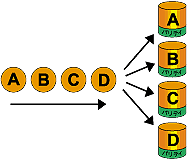
7.RAID 5
RAID 0 の分割アクセスと高速性、パリティ領域を全てのディスクに持たせた冗長性、
またディスク使用効率の経済性とあわせ、バランスの取れたRAIDレベルで、現在RAIDレベルの
スタンダードとなっている。ただし、ディスク台数が多くなればなるほど信頼性と復旧時間が
低下します。また2台同時にディスク障害がある場合は、データが消失します。
8.RAID 5 + スペアディスク
RAID 5 構成にディスク障害時のスタンバイドライブを設定。ディスク障害と同時にスペアドライブに
復旧データを自動的に書き込み、その間もRAID稼動が可能であり、ノンストップ稼動の実現と保守の
自動化を図った推奨RAIDレベル。